
p-value vs. positive predictive value

Riddle me this:
What does it mean if a result is reported as significant at p < 0.05?
A If we were to repeat the analysis many times, using new data each time, and if the null hypothesis were really true, then on only 5% of those occasions would we (falsely) reject it.
B Without knowing the statistical power of the experiment, and not knowing the prior probability of the hypothesis, I cannot estimate the probability whether a significant research finding (p < 0.05) reflects a true effect.
C The probability that the result is a fluke (the hypothesis was wrong, the drug doesn’t work, etc.), is below 5 %. In other words, there is a less than 5 % chance that my results are due to chance.
(solution at the end of this post)
Be honest, although it doesn’t sound very sophisticated (as opposed to A and B), you were tempted to chose C, since it makes a lot of sense, and represents your own interpretation of the p-value when reading and writing papers. You are in good company. But is C really the correct answer?
Results are ennobled by a p-value of less than 0.05: They are significant! Although most biomedical scientists are able to perform statistical tests in Excel or even programs such as SPSS, yet they may fail at the most basic interpretation of what ‘statistical significance’ implies. Indeed, most of them are under the impression that p <0.05 (or any other value that they specify for alpha) is a statement about the probability of the correctness of the biological hypothesis they were testing. They think ‘In less than 5% of the cases I falsely conclude that my theory is correct’. Frequentist, a.k.a. Null hypothesis significance testing (NHST), i.e. the type of statistics 99 % of researchers in biomedicine use, can’t make such a statement (actually, Bayesian statistics can, but that is an altogether different story….). There are at least two principal reasons why p-values can not quantify the probability with which a hypothesis is true or false
1. We do not know what the prior probability of our hypothesis being true or false is. In fact, even if we would know, there is no way to use it in our statistical test. It is not part of the computation!
2. Statistical tests (and hence p-values) concern the data (the sample), not reality (the population). In other words, a flawed experimental design, or a measurement error or bias can produce a highly significant result, but is absolutely meaningless.
Let’s look at this in a bit more detail:
1. Why is prior probability of the hypothesis an issue? Why does a p-value of <0.05 have a very different meaning for the interpretation of the statistical testing of a very unlikely hypothesis (,mind reading is possible’), compared to the testing of a highly probable hypothesis (,Oral intake of norovirus causes diarrhea’)? In the world of frequentist statistics, the positive prediction of a test is determined by three variables: 1) alpha (type I error, aka false positive rate, often set to 0.05); 2) beta (Type II error, aka false negative rate, less well known by many, and those who believe they know about it often think it is only relevant if their test did not achieve a ‘significant’ p-value); and 3) the probability of the hypothesis being true (prestudy odds). Here is an example: At alpha = 0.05 and ß = 0.5 (quite typical for many experimental designs in biomedicine, see Button et al. 2013, and below), and a probability of 20% that the hypothesis is correct, about three-quarters of the significant results (i.e. p<0.05) would represent true positives, and the rest (1/4) would actually represent false positives. So in this quite representative (and conservative!) example the false positive rate would be 25%, and not 5 %, as conventional wisdom dictates. [Formula: Positive Predictive Value = (Power x prestudy odds) / (Power x prestudy odds + alpha)]
2. The other relevant factor is that statistics is applied to the data (i.e. the sample), and not the population from which it came. In other words, the probability given by a test can only be applied to the data. However, the common misinterpretation is to relate it to their explanation (= the hypothesis). Here is a prominent and illustrative example from the physics world: In 2011 the OPERA collaboration reported evidence that neutrinos travel faster than light, a finding which violates Einstein’s theory of relativity and if true would have shattered physics as we know it! Their analysis was significant at the 6 sigma level, even more stringent than the accepted but already brutal 5 sigma level of particle discovery (p=3.5 x 10-7). Extraordinary claims require extraordinary evidence! The results were replicated by the same group, published, and hailed by the world scientific and lay press. The New York times titled ‘Roll over Einstein!’. A short while later it turned out that the GPS systems used in the experiment were not properly synchronized, and a cable was loose. No matter how statistically significant a result is, if it is based on flawed experimental design, or has low internal validity (i.e. is affected by bias, such as selection, performance, or attrition bias) it is worthless.
The point I am making is that many scientists mistake the p-value for the positive predictive value. The positive predictive value (PPV) is the probability that a ‘positive’ research finding reflects a true effect (that is, the finding is a true positive). Since statistical power is such an important determinant of the PPV of our tests (see 1. above, and PPV formula), lets explore it a bit deeper.
3. On power. The more data points you have (sample), the more accurate is the statement about the population from which we draw samples: The more data points we collect, the greater the statistical power of our analysis, and the lower the probability of achieving a false negative result. In clinical biomedicine, a power of at least 0.8 (80%; power = 1-beta, thus ß = 0.2) is required by regulatory autorities and journal editors. Since alpha is usually set to at least 0.05 (see above), this means that in this scenario we are four times more afraid of false positive than of false negative results (4 x 0:05 = 0.2). Statistical power is a big issue in clinical study design, and great care is taken to chose sample sizes that safeguard the prespecified value for beta (80 or 95 %).
In contrast, in most of basic and preclinical life sciences, beta and thus power are not an issue at all. The focus is on achieving a significant p-value, as ‘negative results’ are considered of little value and hard to publish. Once a significant p-value has been obtained, why would you want to talk about beta? Isn’t beta the false negative rate, and if you don’t have a negative result, why should you worry? The reason was already given above: Because beta, just as alpha and the prior probability of your hypothesis determine the chances that the positive result that you are looking at is in fact a true positive. Here is a nice example, which originated from Sterne (2001) and then made it into an issue of the Economist in October 2013 (‘How science goes wrong’) .
For an animated version of the figure, see
http://www.economist.com/blogs/graphicdetail/2013/10/daily-chart-2
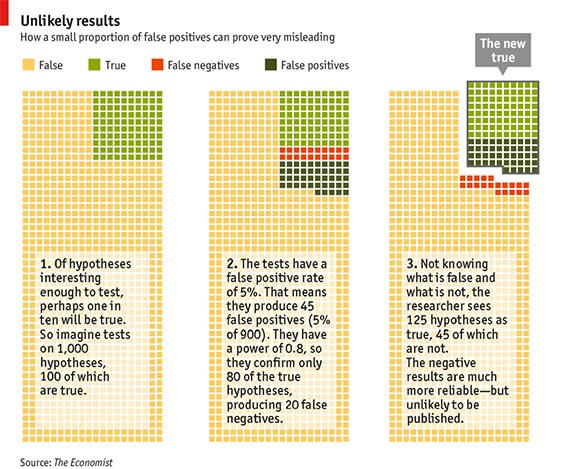
[NB: Since the Economist failed to mention the source of this example, here it is: Sterne&Smith (2001) BMJ 322:226-31]
Imagine that 1000 hypotheses will be tested (in many biomedical fields many more hypotheses have been tested). We set alpha = 0.05 and beta = 0.2, according to good practice in clinical medicine. Now consider the following assumption: 10% of the hypotheses are correct, i.e. 100 of 1000. Due to our alpha and beta levels testing will result in 45 false positives (5% of 900), while 20 of the 100 correct hypotheses will be rejected (20% of 100). Thus, overall 125 of the hypotheses will be considered ‘true’ by the tests (‘the new true’ in the right panel of the figure), but only 80 of them are really true, 45 are in fact false positives. Thus, the error rate was not 5 %, as ‘suggested’ by p<0.05, but 36 %! Maybe you object that the hypotheses you test are much more likely than 10%, rather close to 80 or 90% of them are correct. But why to then still do experiments? This would be counterproductive, because then you only run the risk of diluting your perfect record with false negatives! At this point, however, it should be noted that the typical statistical power of the majority of published studies in preclinical biomedicine is far below 80%. A recent systematic analysis of neuroscience research revealed a median of statistical power under 20% (Button et al., 2013). To clarify: The Power of a coin toss is 50%!
If you have not already done so, I recommend a short post-hoc check of the power of your key experiments. An easy to use, very instructive freeware program for this is available per download from the University of Düsseldorf (http://www.gpower.hhu.de/).
Solution to the question: What does it mean if a result is significant at p < 0.05?
Answers A and B are correct, C is dead wrong.
Related posts in this blog:
Higgs’ boson and the certainty of knowledge: What do those extremely low p-values in physics mean?
Why post-hoc power calculation is not helpful?
Loose cable, significant at p<0.0000002: Statistical significance of a flawed experiment!
Too good to be true: Excess significance in experimental neuroscience
Power failure: Neuroscience as a game of chance!
References and further reading:
Button KS, Ioannidis JP, Mokrysz C, Nosek BA, Flint J, Robinson ES, Munafo MR. Power failure: why small sample size under mines the reliability of neuroscience. Nat Rev Neurosci. 2013 May, 14 (5): 365-76.
Ioannidis JP. Why most published research findings are false. PLoS Med 2005 August; 2 (8): e124.
Kimmelman J, Mogil JS, Dirnagl U Distinguishing in between exploratory and confirmatory preclinical research will improve increase translation. . PLoS Biol 2014 May 20; 12 (5): e1001863.
Sterne JA1, Davey Smith G. Sifting the evidence-what’s wrong with significance tests? BMJ. 2001 Jan 27;322(7280):226-31.

One comment