
The Relative Citation Ratio: It won’t do your laundry, but can it exorcise the journal impact factor?
 Recently, NIH Scientists B. Ian Hutchins and colleagues have (pre)published “The Relative Citation Ratio (RCR). A new metric that uses citation rates to measure influence at the article level”. [Note added 9.9.2016: A peer reviewed version of the article has now appeared in PLOS Biol]. Just as Stefano Bertuzzi, the Executive Director of the American Society for Cell Biology, I am enthusiastic about the RCR. The RCR appears to be a viable alternative to the widely (ab)used Journal Impact Factor (JIF).
Recently, NIH Scientists B. Ian Hutchins and colleagues have (pre)published “The Relative Citation Ratio (RCR). A new metric that uses citation rates to measure influence at the article level”. [Note added 9.9.2016: A peer reviewed version of the article has now appeared in PLOS Biol]. Just as Stefano Bertuzzi, the Executive Director of the American Society for Cell Biology, I am enthusiastic about the RCR. The RCR appears to be a viable alternative to the widely (ab)used Journal Impact Factor (JIF).
The RCR has been recently discussed in several blogs and editorials (e.g. NIH metric that assesses article impact stirs debate; NIH’s new citation metric: A step forward in quantifying scientific impact? ). At a recent workshop organized by the National Library of Medicine (NLM) I learned that the NIH is planning to widely use the RCR in its own grant assessments as an antidote to JIF, raw article citations, h-factors, and other highly problematic or outright flawed metrics.
I think the RCR is very smart and useful, and should be seriously considered by funders and institutions worldwide not “as a tool to be used as a primary criterion in funding decisions, but as one of several metrics that can provide assistance to decision-makers at funding agencies or in other situations in which quantitation can be used judiciously to supplement, not substitute for, expert opinion”, as Hutchins et al. cautiously point out.
The JIF has already been convincingly refuted so many times as a measure of the impact, quality, or influence of the work of individual scientists. Repeating the arguments may even raise the suspicion that there may be something wrong with them. Nevertheless, it is my experience that many of my colleagues, besides having a bad gut feeling about it, are not aware of the collective conceptual and quantitative evidence against its current use. I am therefore summarizing the case against the IF (with some data/examples), before I turn to the RCR and argue why in my view it is the perfect tool to exorcise the JIF. If I am preaching to a convert, please skip to ‘The relative Citation Ratio’ below.
The Journal Impact factor
Much has been written about the multiple misuses and flaws of the JIF, (for example Wrong Number: A closer look at Impact Factors or Brembs et al Deep impact: unintended consequences of journal rank), and declarations have been signed (San Francisco Declaration on Research Assessment).
Here is my personal summary of what is wrong with it:
The criteria and mechanisms by which academic researchers are hired, receive tenure, or acquire funding are ultimate determinants of the product of their science: new knowledge. Rewarding only spectacular results will produce spectacular results, irrespective of their robustness and reliability . Rewarding exclusively robustness will lead to highly reliable, but potentially dull results. The current system of rewarding and incentivizing biomedical research is heavily biased towards spectacular results, as the prestige of the journals in which the results are published is the main metric of success (for an evolutionary perperspective, see The Natural selection of bad science, Smaldino and McElreath). Conveniently, this prestige, or influence, can be quantified by the Impact Factor (JIF). The main advantage of the JIF is that it is easily computed, and can be understood by a four year old: For any given year and journal, the JIF is the number of citations to articles published in the previous two years divided by number of articles published. It is a measure of a journal’s impact, and does not tell you anything about an article published in it. Unless you are a journal editor or a publisher, you shouldn’t worry about it.
The JIF is a very convenient metric. If a medical faculty wants to incentivize the research of its clinicians and scientists, it can simply add up the impact factors of the journals in which a particular researcher has published in a certain period (e.g. last 3 years). This factor is then multiplied by a sum of money set aside for rewarding researchers in a performance based manner. This sum will be handed to the researcher as a supplement to the funds that he or she acquires via foundations and other funding agencies. This is how we do it at the Charité, one of Europe’s largest academic medical centers and schools, and at many other medical faculties in Germany. Roughly 5 Mio € are distributed every year to clinicians and researchers at the Charité according to this simple algorithm. At the press of a button, on an individual basis, performance oriented, absolutely quantitative, totally objective. Brought to you via the JIF, for thousands of journals, by Thomson Reuters.
It’s a beautiful metric. The JIF does make life so much easier for committees and funders. You can do so many things with it, which would otherwise be tedious, time consuming, and subjective. For example, if you integrate the JIF of a researcher over a certain period (say 5 years), you get one figure for his or her productivity and scientific impact! Faster than you can read an abstract, after sorting it in a spreadsheet of applicants you have got a shortlist of candidates! Of course with the necessary caveat and some regret that this is not perfect, but the best of all worse approaches. If you then go the extra mile, and count how many entries from the ‘CNS’ (i.e. Cell/Nature/Science) category an applicant has, you are almost done. Without reading a single paper or asking a question, you know how productive and influential a candidate is.
The JIF and its derivatives (for example when it is field normalized) are so attractive that they have become the de facto world currency of scientific success. Despite the fact that everybody knows that this approach is flawed. And that its misuse is one of the root causes of the current crisis in the rigor, reproducibility, and responsibility of biomedical research. Much has already been written about it, here is a list of some of the problems:
- Most fundamentally, it is not a measure of the originality, relevance, quality, robustness or impact of an individual article and thus of an author. It is a reflection of the yearly average citations to articles published over two years preceeding the year in which the JIF is calculated. It is not an article-level metric of influence or impact of an individual paper, but one of journal importance and editorial policy. This is where all the problems start.
- The JIF does not account for the differences in the influence of individual papers. Citation distributions within journals are highly skewed. For example, about 90% of Nature’s impact factor is based on only a quarter of its publications. Which means that only a small fraction of papers receive most of the citations, and are responsible for the JIF, which is calculated as the mean, not the median of citations. Most articles in the top IF journals (‘CNS’: Cell-Nature-Science, etc.) do not receive more citations that articles in other scholarly journals with much lower JIF. Here is a graphic example from a year in which the JIF for Nature Neuroscience was 15.14, for J Neurosci 8.05, for Brain Research 2.474, and for Nature 30.98 (taken from Nat Neurosci). Don’t they look conspicuously similar?
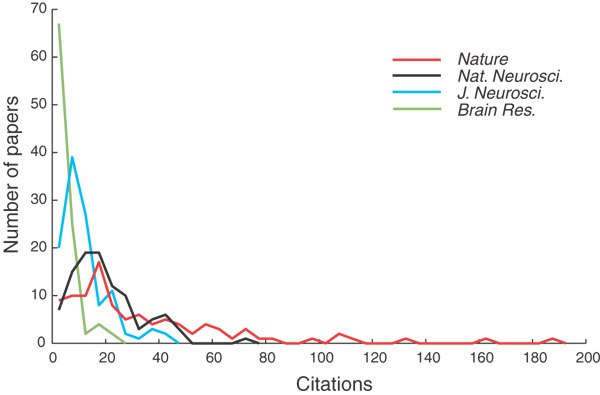
“The most obvious feature of these distributions is that they are highly skewed in every case, the medians are lower than the means, reinforcing the point that a journal’s JIF (an arithmetic mean) is almost useless as a predictor of the likely citations to any particular paper in that journal” (Editorial, Nature Neuroscience)
- The JIF does not consider that different fields have different access to top-tier publication venues. The problems of comparing impact factors across disciplines can easily be demonstrated by comparing the JIF of the top journal in various fields. In 2016, the top journal in the category ‘Biochemistry and Molecular Biology’ has an impact factor of 30.357 compared to 4.949 for the top journal in the category ‘Dentistry, Oral surgery and Medicine’. It is nonsensical to suggest that biochemistry journals are more than 6 times better or important than dentistry journals. Let alone individual articles in them. Nor does it account for the fact that different fields have different citation cultures, and importantly, that large fields produce more citations
- The JIF can be, and often is, manipulated, or “gamed” by editorial policy. Here is an example from Phil Davis (Citable Items: The Contested Impact Factor Denominator). Check out the rise of editorial material of papers published in the NEJM, JAMA, The Lancet, and The BMJ. Data source: Web of Science. Editorial material receives citations, but does not count as citable item. In other words, Editorial material increases the impact factor. Many of the journals take this one step further, by labeling original material as editorial content, such as ‘mini-reviews’ etc.

Not surprising, the first-ranked journal in the subject category listings will often be a review journal. Excluding review articles in the calculation of the JIF would substantially decrease the JIF of most journals because they publish (as much as they can) reviews together with original articles.
- Data used to calculate the Journal Impact Factors are neither transparent nor openly available to the public. Calculation methods, especially what items are excluded from the total article count for the cited journal under consideration are not disclosed. See “Show me the data” by Rossner, Van Epps, and Hill ).
- Citations to a paper are strongly influenced by the impact factor of the journal. It becomes a self fulfilling prophecy. Citations received by a given paper do not only reflect the ‘quality’ of that paper but also that of the journal in which it is published. This can be empirically demonstrated. Here is an example (taken from Stuart Cantrill). An identical paper was published in a number of journals, see how perfectly the number of citations correlate with the JIF:
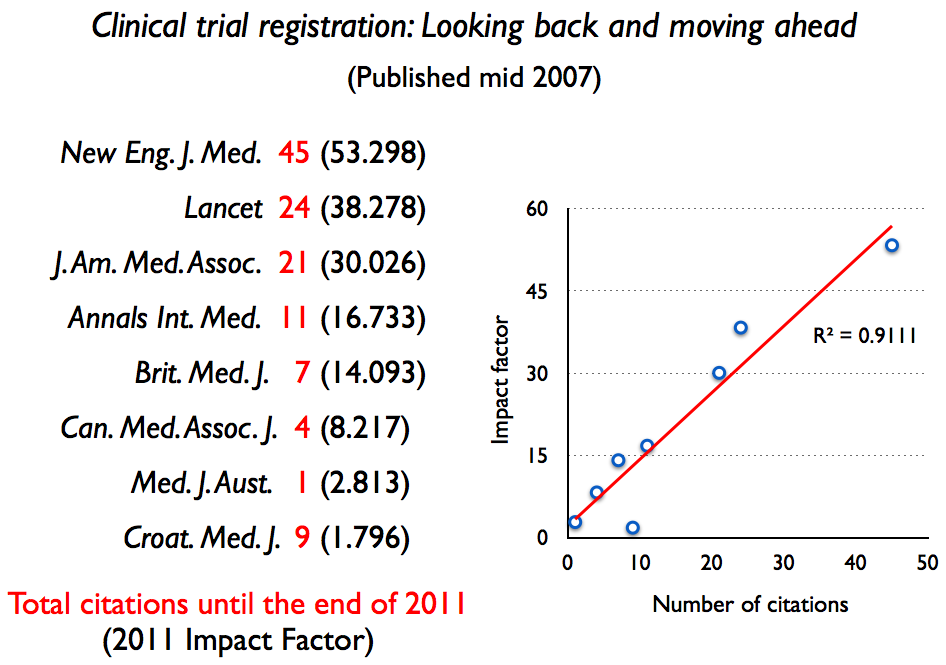
In another study, Vincent Larivière and Yves Gingras compared 4,532 pairs of identical papers published in two journals with different impact factor, and found “there is a specific Matthew effect attached to journals and this gives to paper published there an added value over and above their intrinsic quality”. (The impact factor’s Matthew effect: a natural experiment in bibliometrics)
One last note on the JIF and journal prestige: With the help of Thomson-Reuters, Journal publishers (Springer-Nature, Elsevier, etc.) are “mining” it out of thin air, creating profit margins topped only by trafficking drugs. Bitcoins also represent value produced out of thin air. But while the mining of Bitcoins is done by number crunching algorithms on computers producing heat, the JIF is mined for publishers by the work of academics (we do the research, write it up, submit it, review it, our libraries subscribe to it, etc.), and the academic reward system, which uses it as its main currency. In the end the taxpayer shoulders the bill.
And here is another consequence of our JIF mania. As Björn Brembs and colleagues put it:
“Even if a particular study has been performed to the highest standards, the quest for publication in high-ranking journals slows down the dissemination of science and increases the burden on reviewers, by iterations of submissions and rejections cascading down the hierarchy of journal rank”
[Note added 9.7.2016: See also Nature Commentary, Beat it, impact factor! Publishing elite turns against controversial metric, as well as comment in Science ‘Hate journal impact factors? New study gives you one more reason‘ and corresponding paper by senior employees at several leading science publishers (Nature, Science, EMBO, ELife….), which appeals to publishers to downplay the JIF in favour of a metric that captures the range of citations that a journal’s articles attract. A simple proposal for the publication of journal citation distributions]
The Relative Citation Ratio
So can we do better? Everyone agrees that science or scientists should not be gauged on simple indicators, and that there is no substitute to reading the papers, talking to the scientists, and expert evaluation. But it is also clear that in many cases this is not practical or even feasible, as for example if you want to reward all individual researchers of a large institution in a performance oriented manner (see the Charité example, above). In addition, expert assessments are good, but also subjective, and may benefit from some additional metric that evaluates individual scientific impact objectively, based on transparent, intelligent, and validated criteria.
There is no doubt that citations somehow must reflect the influence of an article and hence its authors. It is quite likely that a paper that is not cited at all did not make any impact, while one that is highly cited is influential. However, raw citations are not a very useful metric. The value of one citation can not be compared to another. Different fields have different citation cultures and the number of potential citations correlates with the size of the field. So counting raw citations values quantity over quality, and does not normalize according to field. Obviously, older articles had more time to collect citations than recent ones. The Hirsch (h) – factor, a derivative, has the same drawbacks, in addition it disadvantages early career researchers. So the solution must somehow lie in ‘normalizing’ the influence of an article using citations to it. This is where the RCR comes in.
The inventors of the RCR set out to create a citation based metric that has the following features:
- Must be article-level based.
- Field normalized but field independent. ‘Fields’ should be defined by the authors or citing researchers, not by pre-set categories.
- Time (for collecting citations) normalized.
- Benchmarked to peer performance and correlated to expert opinion.
- Freely accessible, transparent.
- Customizable, allowing the comparison of portfolios of either teaching or research oriented institutions, or within developing nations (‘Comparing apples to apples’).
The JIF, or its more complex derivatives (citation normalization to field categories, Eigenvector normalization, Source normalized impact) score nil-6 in the above feature list. The RCR, as described by Hutchins et al., on the other hand, fulfills all those criteria. In a abstract terms (for details, please refer to their highly accessible paper):
“The RCR uses the co-citation network of each article to field- and time-normalize it by calculating the expected citation rate from the aggregate citation behavior of a topically linked cohort. An average citation rate is computed for the network, benchmarked to peer performance, and used as the RCR denominator; as is true of other bibliometrics, article citation rate (ACR) is used as the numerator.” (quoted from)
The essence of the RCR was nicely summarized by Ludo Waltman:
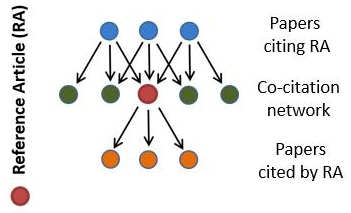
“In a simplified form, the idea of the RCR metric can be summarized as follows. To quantify the impact of a publication X [RA =reference article in the figure below], all publications co-cited with publication RA are identified. A publication Y is co-cited with publication X if there is another publication in which publications X and Y are both cited. The publications co-cited with publication X are considered to represent the field of publication X. For each publication Y belonging to the field of publication X, a journal impact indicator is calculated, the so-called journal citation rate, which is based on the citations received by all publications that have appeared in the same journal as publication Y. Essentially, the RCR of publication X is obtained by dividing the number of citations received by publication X by the field citation rate of publication X, which is defined as the average journal citation rate of the publications belonging to journal X’s field. By comparing publication X’s number of citations received with its field citation rate, the idea is that a field-normalized indicator of scientific impact is obtained. This enables impact comparisons between publications from different scientific fields.”
Figure 1a from the original paper illustrates the idea of the co-citation network:
You don’t have to calculate it yourself, a free online tool, iCite is provided alongside the paper:
“iCite is a tool to access a dashboard of bibliometrics for papers associated with a portfolio. Users upload the PubMed IDs of articles of interest (from SPIRES or PubMed), optionally grouping them for comparison. iCite then displays the number of articles, articles per year, citations per year, and Relative Citation Ratio (a field-normalized metric that shows the citation impact of one or more articles relative to the average NIH-funded paper). A range of years can be selected, as well as article type (all, or only research articles), and individual articles can be toggled on and off. Users can download a report table with the article-level detail for later use or further visualization.” (from the iCite landing page)
In their article, Hutchins et al. validate the RCR against three independent expert scores (for details, see the article). The bottom line is that the RCR correlates very well with reviewer’s judgements.
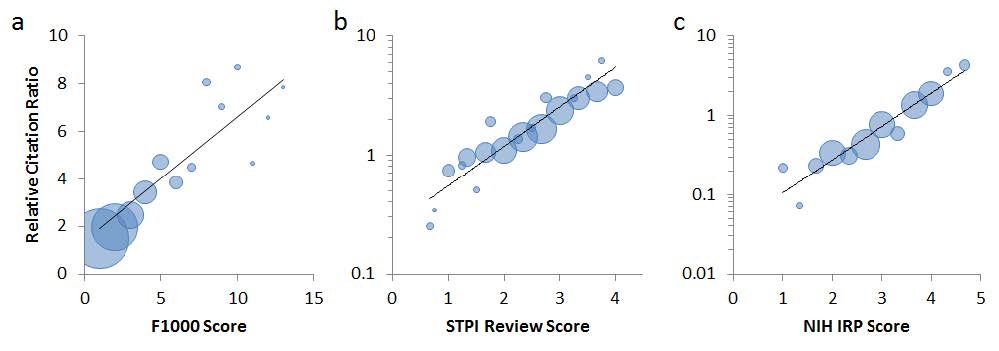
Figure 3. Relative Citation Ratios correspond with expert reviewer scores. (a-c) Bubble plots of reviewer scores vs. RCR for three different datasets. Articles are binned by reviewer score; bubble area is proportionate to the number of articles in that bin. (a) F1000 scores for 2193 R01-funded papers published in 2009. Faculty reviewers rated the articles on a scale of one to three (“Good”, “Very Good”, and “Exceptional”, respectively); those scores were summed into a composite F1000 score for each article (Supplemental Figure 3). (b) Reviewer scores of 430 HHMI and NIH-funded papers collected by the Science and Technology Policy Institute. (c) Scores of 290 R01-funded articles reviewed by experts from the NIH Intramural Research Program. Black line, linear regression. (figure 3 from Hutchins)
Finally, Hutchins et al. did a field study on >88000 papers authored by >3000 NIH funded researchers and published from 2003 to 2010. Each scientist had succeeded in renewing their grants at least once. This revealed interesting insights in the RCR compared to the JIF (summarized in the figure below, fig 4 from Hutchins). RCR values for these articles followed a log-normal distribution, while the JIF distribution was non-normal. They also show that influential science is often published in journals which are not top-tier according to JIF.
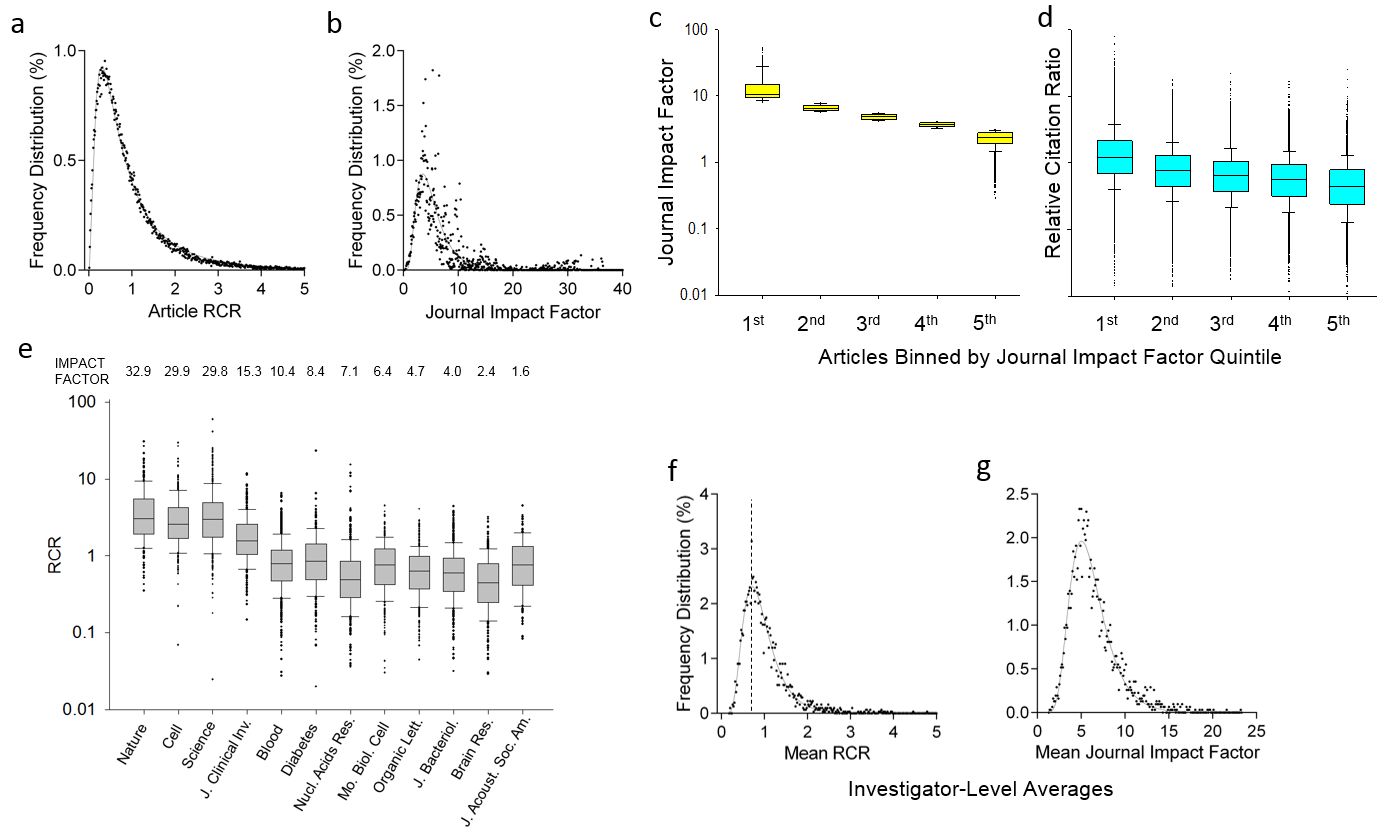
Figure 4. Properties of Relative Citation Ratios at the article and investigator level. (a, b) Frequency distribution of article-level RCRs (a) and Journal Impact Factors (b), from 88,835 papers (authored by 3089 R01-funded PIs) for which co-citation networks were generated. Article RCRs are well-fit by a log-normal distribution (R2 = 0.99), and Journal Impact Factors less so (R2 = 0.79). (c) Box-and-whisker plots summarizing Journal Impact Factors for the same papers, binned by Impact Factor quintile (line, median; box, 25th–75th percentiles; whiskers, 10th to 90th percentiles). (d) RCR for the same papers using the same bins by Journal Impact Factor quintile (same scale as c). Although the median RCR for each bin generally corresponds to the Impact Factor quintile, there is a wide range of article RCRs in each category. (e) Box-and-whisker plots summarizing RCRs of these same papers published in selected journals. In each journal, there are papers with article RCRs surpassing the median RCR of the highest Impact Factor journals (left three). The Impact Factor of each journal is shown above. (f, g) Frequency distribution of investigator-level RCRs (f) and Journal Impact Factors (g), representing the mean values for papers authored by each of 3089 R01-funded PIs. Dashed line in (f), mode of RCR for PIs. (figure 4 from Hutchins )
In conclusion, the RCR appears to be well suited to measure the influence of an article. With caution it may be used as a supplementary tool to assist in the evaluation of science and scientists, at least in biomedicine. I applaude the authors for sharing their article as a preprint and providing the acompanying software tool, and the NIH for spearheading the process of abandoning flawed metrics.
[Note added 27.07.2016:Digital Science to Adopt Relative Citation Ratio Developed at NIH ]
[Note added 09.09.2016: For a balanced discussion on the various ways to normalize citation metrics, including the RCR, see Ioannidis JPA, Boyack K, Wouters PF (2016) Citation Metrics: A Primer on How (Not) to Normalize. PLoS Biol 14(9): e1002542. doi:10.1371/journal.pbio.1002542]

You have provided an excellent summary and critique of this new metric Uli! I agree fully that new metrics such as the RCR will likely be useful in challenging untoward effects of the JIF and in combating the continued production of spectacular results that ultimately do not hold up over time. Many thanks for this,
Robert Thorne
University of Wisconsin-Madison